






Your Data Platform Is the Bottleneck. Your AI Strategy Is Not.
A common pattern, observed across roughly thirty AI engagements we have been part of in the last two years: the client believes they have an AI problem. After a week of diligence, the problem reveals itself as a data problem. The data is in the wrong places, in the wrong shapes, with the wrong access patterns, owned by the wrong teams, governed by the wrong policies, and updated on the wrong cadences. The AI strategy assumes a data platform that does not exist. The strategy will not survive contact with the existing one.
This is not a corner-case observation. This is the central observation. The AI strategies that are succeeding in 2026 are the ones that started with a data platform that was already, independently, in good shape. The ones that are failing are the ones that built an AI program on top of a data platform that was failing the business before AI ever entered the conversation.
The Symptom Pattern
The symptoms are almost identical from client to client.
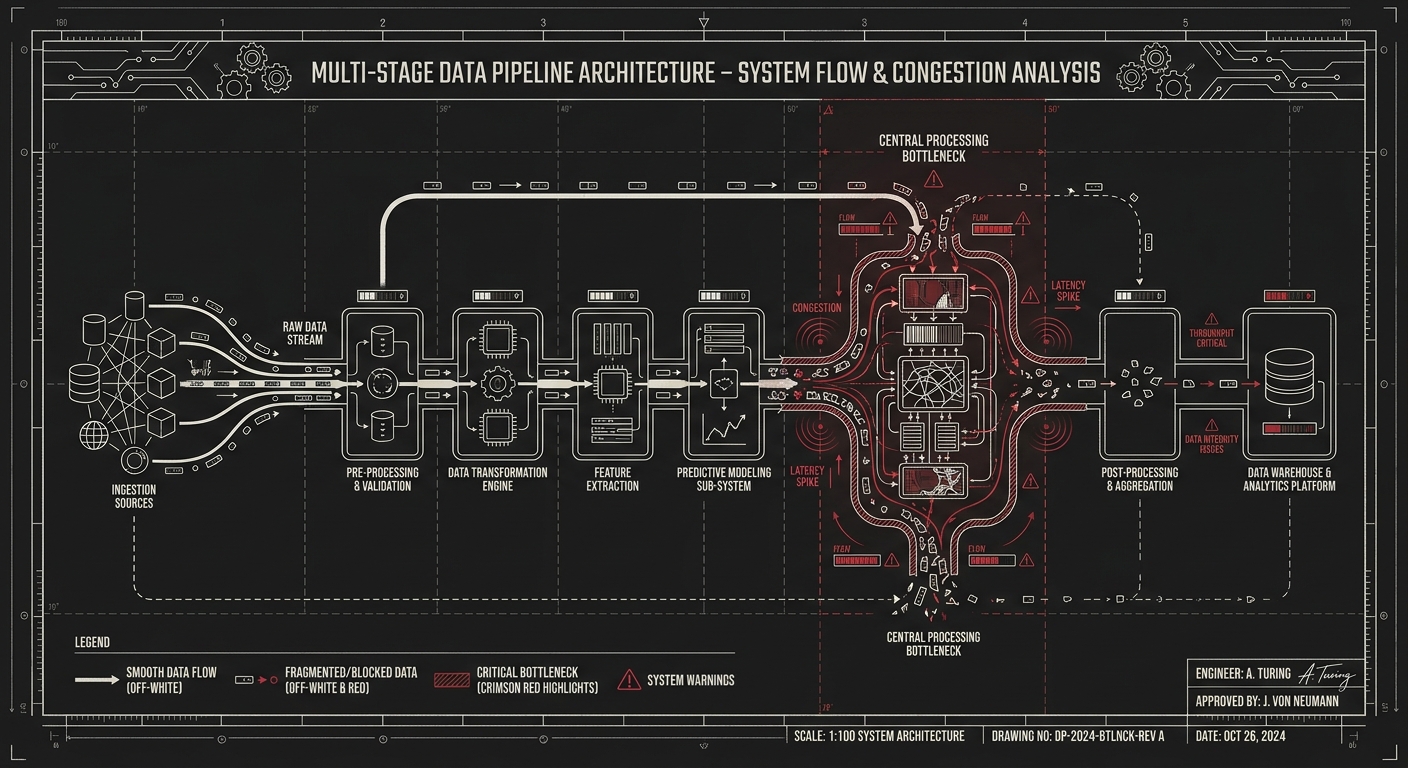
The retrieval-augmented generation pipeline returns plausible-looking results that, on inspection, are derived from outdated documents because the ingestion pipeline runs weekly and the source systems update daily.
The agent makes confident decisions on customer-segment data that turns out to be a partial mirror of the production CRM, missing the last six months of changes because the ETL job that maintains the mirror has been silently failing.
The model fine-tune is trained on a “curated” dataset that the data team assembled from five source systems, each of which uses a different definition of “active customer,” and the discrepancies were resolved by the fine-tune in ways nobody documented.
The internal evaluation tool measures the agent’s accuracy against a ground-truth dataset that was generated by a different agent six months ago, which means the evaluation is mostly measuring agreement with the previous agent’s mistakes.
These are not AI failures. These are data failures that the AI is making visible. The AI did not break the system. The AI is the first system that was forced to actually use the data end-to-end without a human in the loop to silently correct for the breakage.
Why Data Quality Used to Be Survivable
For most of the history of enterprise data, the data platform was a human-mediated system. Humans wrote the queries that consumed the data. Humans interpreted the results. Humans noticed when a number looked wrong, asked the data team about it, and either got an explanation or refused to act on the number until they got one.
This human mediation was extraordinarily forgiving of data quality problems. A dashboard with three subtly wrong numbers was usable, because the human looking at the dashboard would notice the discrepancy with their own intuition and either flag it or ignore it. A report with a stale field was usable, because the human reading the report would know the field was stale and discount it accordingly. The data platform was reliable enough to support the work being done on top of it, and the unreliable parts were absorbed by the humans.
The data platform did not have to be excellent. It had to be good enough to support human decision-making, and humans are tolerant systems.
AI is not tolerant. The agent does not notice that a number looks wrong. The agent operates on the data as given. If the data is wrong, the agent’s decisions are wrong, propagated at machine speed across thousands of cases, without the local human correction that used to absorb the noise. The same data platform that supported a hundred analysts for ten years cannot support fifty agents for ten weeks. The agents expose what the analysts were silently working around.
What “Fixing the Data Platform” Actually Means
The phrase “fixing the data platform” gets used as a euphemism for almost anything. Be specific about what it means in this context.
Authoritative sources, named and documented. For every data class – customers, transactions, products, employees, whatever the business domain calls them – there is exactly one authoritative source, named, documented, and known to every team that consumes the data. The authoritative source is the system of record. Every other system that contains the same data is a derivative. The derivatives are kept in sync via documented pipelines with documented latency, and the documentation is updated when the pipelines change.
Definitions, ratified and enforced. “Active customer” means one thing across the organization, written down, and used consistently. The definition is owned by a named human. When a new system needs the definition, the new system uses the canonical one. When the definition has to change, the change is announced, dated, and propagated. Most data platforms have multiple incompatible definitions of the same business concept in active use. Fixing this is unglamorous and load-bearing.
Freshness, measured and reported. Every derivative dataset has a known freshness. The freshness is measured continuously, reported, and alerted when it degrades. “Updated daily” is not a freshness statement; “last successful refresh: 2026-06-01 03:14 UTC” is. Agents need the second kind. Analysts could survive on the first.
Access, scoped and audited. Every data access – by humans, by services, by agents – is logged, attributed, and reviewable. Not for compliance theater. For operational reality: when an agent makes a wrong decision, you need to be able to look at exactly which records it read, when, and through which interface. Without this, agent debugging is impossible.
Quality, measured at the boundary. Data quality is not a property of a dataset in isolation. It is a property of a dataset’s fitness for a specific use. Each downstream use case has its own data quality requirements. Those requirements are documented at the boundary between the platform and the consumer. When the platform stops meeting a use case’s quality bar, the use case is notified before the consumer notices the failure.
None of this is AI-specific. All of this is the data engineering practice that should have existed before AI arrived. AI is the forcing function that makes the absence of this practice expensive.
The Sequencing Question
The hardest question for most clients is the sequencing question. Do we fix the data platform before we build the AI program, or in parallel, or after?
The answer is contextual but rarely “after.” The orgs that try to ship AI products on top of a broken data platform spend most of their delivery time fighting the platform’s deficiencies inside the AI codebase. They build custom retrieval logic that compensates for a broken ingestion pipeline. They build adjudication logic that resolves conflicting definitions from upstream sources. They build evaluation harnesses that work around stale ground truth. These workarounds become the AI codebase, which means the AI codebase becomes a second data platform built on top of the broken first one. This is a recipe for permanent dual maintenance and eventual abandonment of the AI program when the workarounds become unmaintainable.
The orgs that get the sequencing right either invest in the data platform first, and then build AI on top of a sound foundation, or invest in both at once, with a clear architectural rule that the AI program is forbidden from compensating for data platform deficiencies. Every time the AI team encounters a data platform problem, it gets escalated to the data platform team, not papered over inside the agent.
The second pattern is more common in practice, because few organizations are willing to defer the AI program for the year it would take to fix the data platform first. The pattern works, but requires real organizational discipline. The temptation to work around the platform inside the AI code is constant. Resisting it is the work.
The Honest Statement
The AI program your executive team is excited about is sitting on top of a data platform that was built for analysts and tolerates human-mediated quality. The platform was never tested by a non-tolerant consumer. The AI program is that consumer.
If you do not address the platform, the AI program will spend its budget building workarounds, ship slowly, deliver inconsistently, and eventually be abandoned. If you do address the platform, the AI program will sit on top of a foundation that supports the entire organization, not just the AI use cases. The platform investment is the larger and more durable one.
The strategy your executive team needs to hear is not “we will build AI.” It is “we will fix the data platform so that AI – and everything else that uses data – works correctly on top of it.” That is a harder sell to a board, and a better one for the business.

